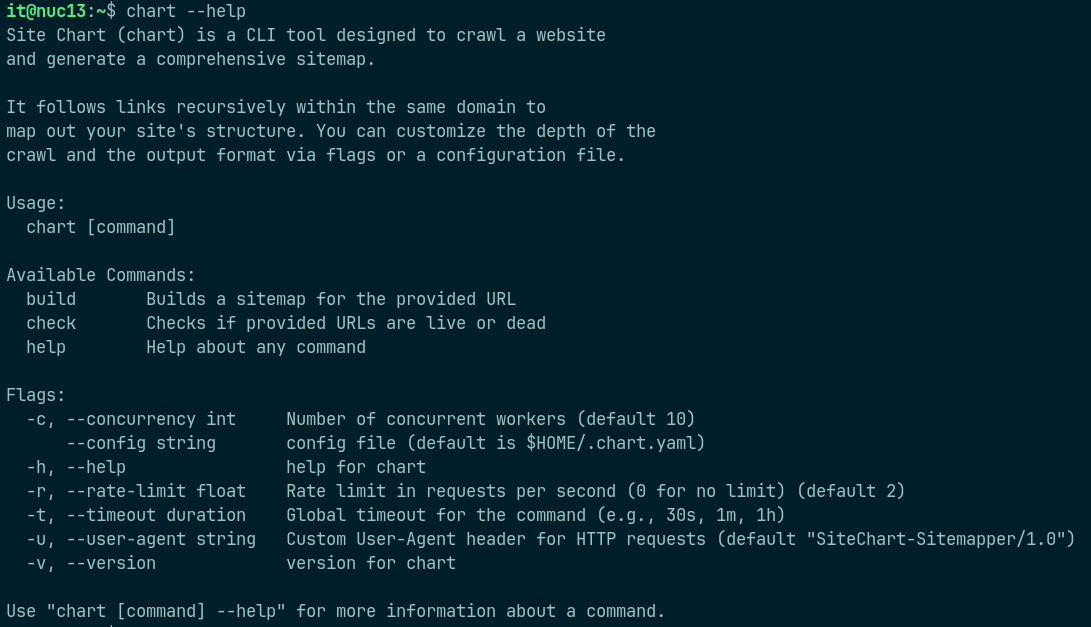
Site Chart: Concurrent Web Crawler in Go
Problem: Real-world web crawling faces complex hurdles: infinite loops from malformed URLs, memory leaks from unmanaged goroutines, and being blocked due to aggressive "impolite" request rates that overwhelm target servers.
Action: Developed Site Chart, a CLI tool using a Semaphore-based Worker Pool. I implemented a custom ticker-based throttler to manage requests-per-second (RPS), and a URL normalization engine to ensure system stability and responsible data fetching.
Result: Site Chart - a robust, high-speed crawler and link validator featuring:
- Throttled Concurrency: Precisely balances high-speed link validation with server-side rate-limiting requirements.
- Recursive Mapping: Implemented depth-controlled crawling to generate comprehensive XML or TXT sitemaps for complex site architectures.
- Normalization Engine: Custom package to handle relative paths and fragments, preventing duplicate crawls and infinite loops.
- 12-Factor Configuration: Fully configurable via YAML, Env variables, or CLI flags through the Cobra/Viper ecosystem, making it portable across different environments.
- Production Safety: Achieved 85%+ average test coverage in core logic and verified 100% thread-safety via the Race Detector.
- Unix Integration: Optimized for DevOps pipelines with support for standard input (stdin) piping, allowing it to chain with other CLI tools for batch link checking.
Project Gallery
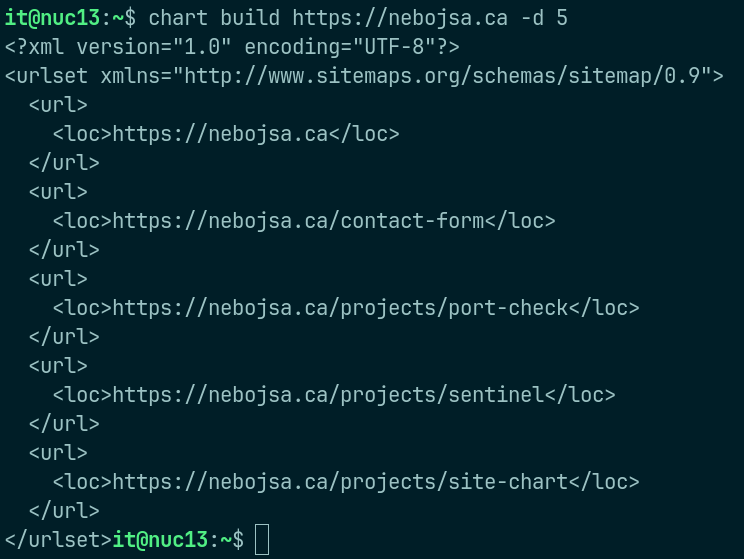
Sitemap Generation (XML): Recursive crawl output formatted as a standard XML sitemap for SEO engine ingestion.
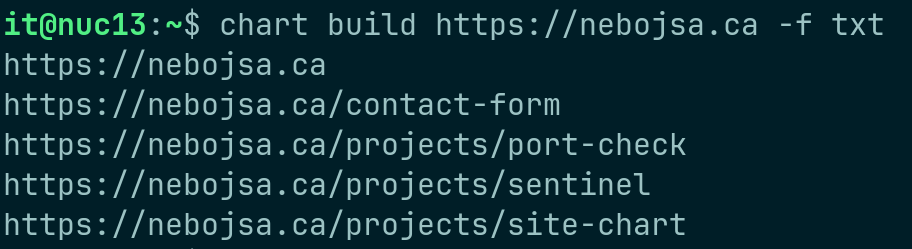
Sitemap Generation (TXT): Flat-file URL list generated via depth-controlled crawling, optimized for quick grep/awk processing.
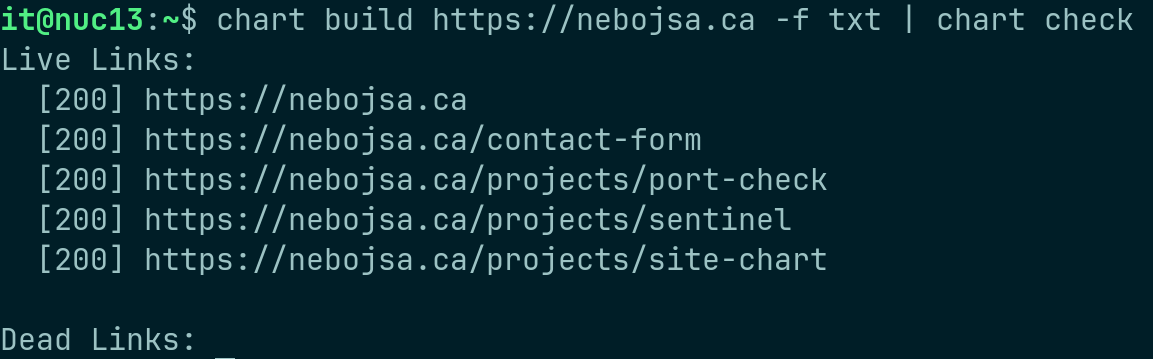
Link Validator: Concurrent HTTP status verification of batches of URLs. Demonstrates using pipe to pass the data to the chart check command.
Reliability: 85%+ average test coverage of internal packages, and race detection verified to ensure production-grade stability.

About: Output of the chart help command showing Cobra/Viper commands and flags.